
Case Study in Yelp Reviews using Spark ML
Problem Statement
To predict the user id of a Yelp Review based on the content of the review. I have done this by building classification models based on past yelp data. Pyspark libraries with Spark 2.4 and Python 3.6.6 :: Anaconda, Inc. are used to cleanse and analyze the data. I executed the jupyter notebook on a CentoOS 7 VM with 16GB Ram, 8 processor cores.
Data Set:
The Yelp collection of reviews can be downloaded from the Kaggle website.
The data file of interest is:
File Name: yelp_academic_dataset_review.json
File Size: 4.39GB
File Format: JSON
Data Exploration
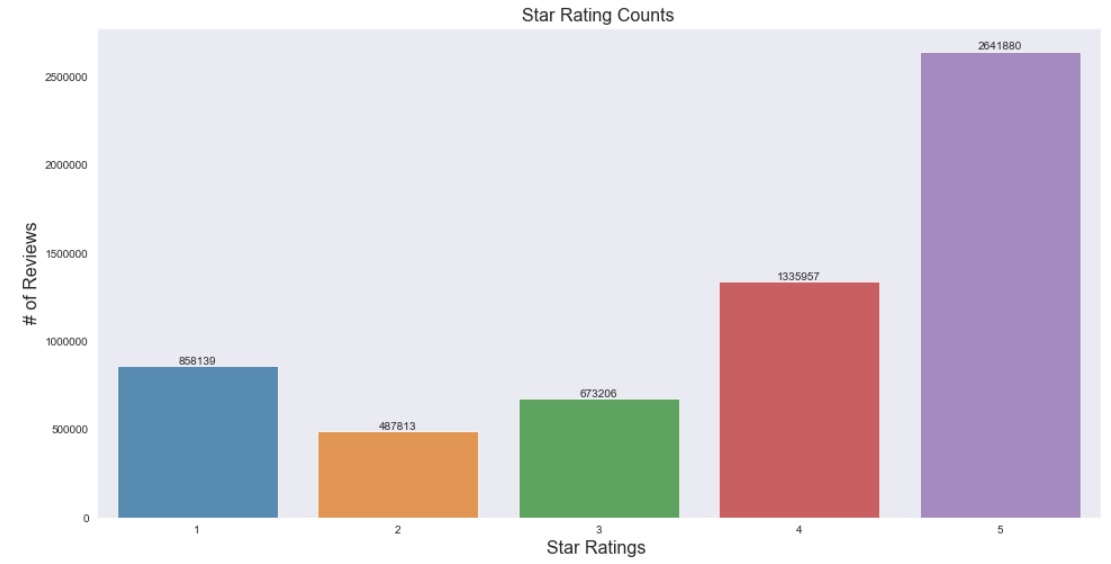
The data contains 6 million rows with 9 columns. Star counts show that on average, the reviews are generally positive, with maximum of reviews being 5 stars.
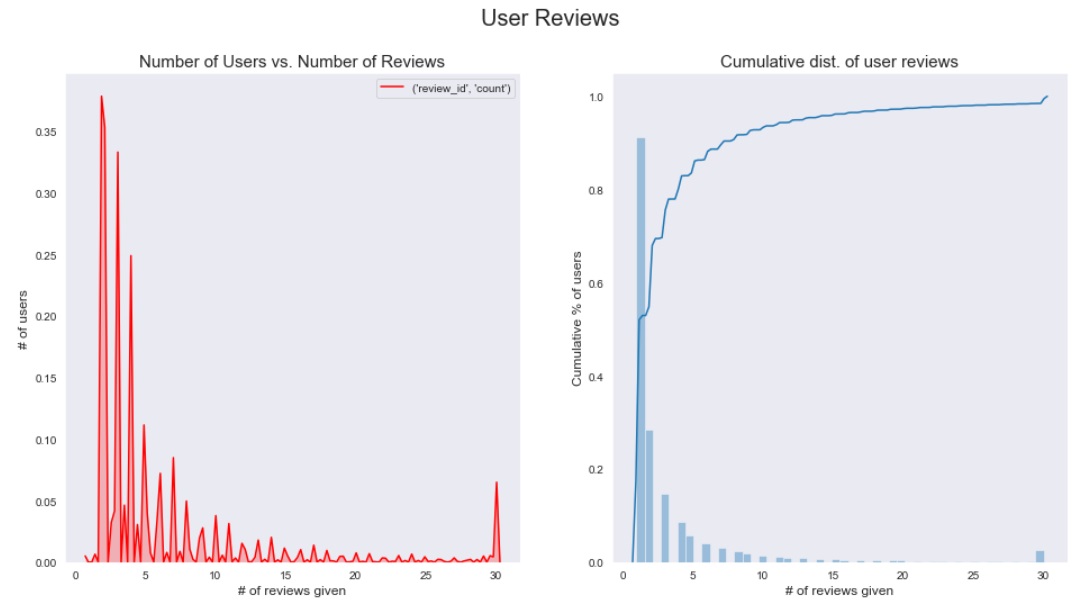
The plots below show that 90% of users have less than 5 reviews. There is a small peak at 30 reviews as it represents all users having 30 or more reviews.
The jupyter notebook containing code for data exploration and visualization is here.
Model Analysis
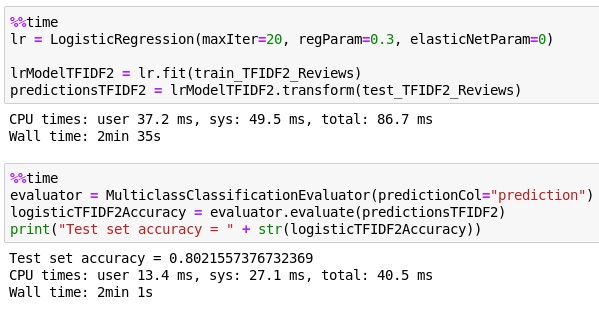
I created logistic regression and naive bayes models with count features, TFIDF features, and TFIDF features combined with n-grams. The highest test set accuracy was 80% for logistic regression with uni-gram and bi-gram TFDIF matrix.
The code below creates a TFIDF matrix of 1 word and 2 word combinations that occur in atleast 10 documents, to a maximum of 1000. Models are trained on the combined features, and test instance predictions are made. Jupyter notebook containing code for all models is here.
Pipline with TFIDF and N-grams:
%%time
reviewsTF = HashingTF(inputCol="words", outputCol="rawFeatures_1", numFeatures=10000)
reviewsIdf = IDF(inputCol="rawFeatures_1", outputCol="features_1", minDocFreq=10)
ngram = NGram(n=2, inputCol="words", outputCol="ngrams_2")
reviewsTF2 = HashingTF(inputCol="ngrams_2", outputCol="rawFeatures_2", numFeatures=10000)
reviewsIdf2 = IDF(inputCol="rawFeatures_2", outputCol="features_2", minDocFreq=10)
pipeline1 = Pipeline(stages=[reviewsTF , reviewsIdf])
pipeline2 = Pipeline(stages=[ngram, reviewsTF2 , reviewsIdf2])
finalPipeline = Pipeline(stages=[regexTokenizer,pipeline1, pipeline2,
VectorAssembler(inputCols=["features_1", "features_2"], outputCol="features"),label_userID
])
pipelineTFIDF2Fit = finalPipeline.fit(top_user_reviews)
top_user_reviews_TFIDF2_features = pipelineTFIDF2Fit.transform(top_user_reviews)
(train_TFIDF2_Reviews, test_TFIDF2_Reviews) = top_user_reviews_TFIDF2_features.randomSplit([0.8, 0.2], seed = 12345)
Logistic Regression
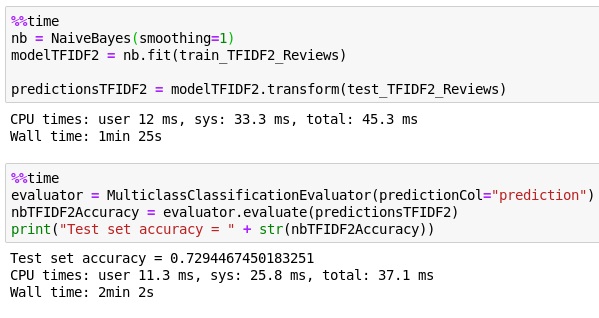
Naive Bayes
Conclusion
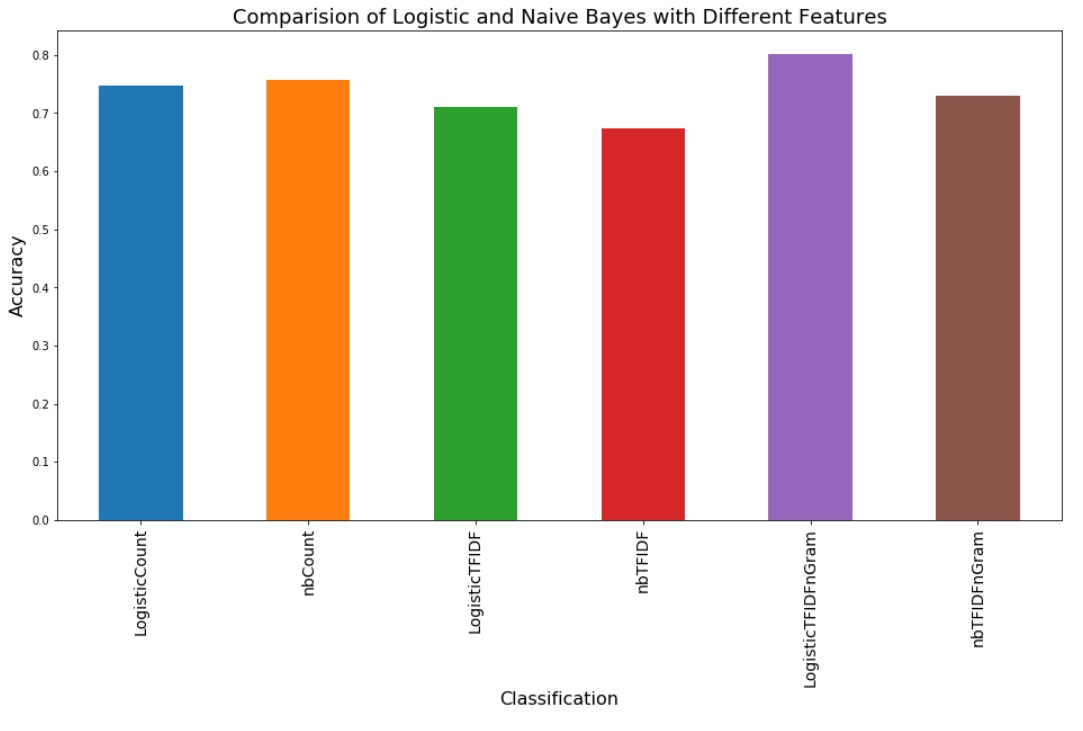
I was surprised that a simple model as logistic regression could give an accuracy of 80% for 76 classes, with just 600 reviews per review. The highest accuracy was achieved when bigrams were included which is expected as users would have unique ways of combining two words together. I did not remove stopwords in this case as how common words are used tell us more about the writing pattern of a user than specific topical words. My assumption is trigrams will improve the accuracy further or it could possibly overfit. Regardless, that would generate a very sparse matrix, which would need to be reduced using LDA for the algorithm to run faster.
References:
Apache Spark ML main guide.
Multi-class classification in Spark.
Leave a comment