

Shakespeare plays analysis
Motivation
The aim of this post will be to analyze Shakespeare plays and determine whether some of the plays or parts of plays were not written by Shakespeare. The code is detailed in the jupyter notebook.
Description
A number of Shakespeare plays along with its sections are given in a data-set available in Kaggle. The data-set is cleaned by dropping the NA values. After that, various sub-section lines are merged into a single section. For example, the sub-sections like 1.1.1, 1.1.2, etc are merged into 1.1.
Once the data is grouped into sections, various syntactic, semantic and functional features of the sections are extracted and clustered to identify the sections which have not been written by Shakespeare. Since, it is very unlikely that Shakespeare might not have any contribution to the whole play, our analysis was done on various sub-sections of the plays. Also, it will help us give a more granular picture on the various sections across different plays which might not have been written by Shakespeare/
Feature Extraction
- Word Analysis: Stats such as average and standard deviation of the number of words in a sentence, and the diversity (number of unique words vs. total words) were collected for each section.
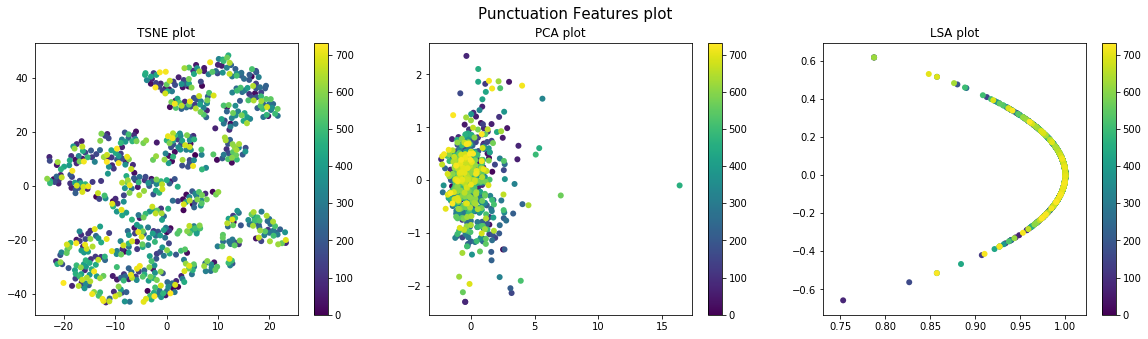
- Punctuation analysis: An author’s signature can include the unique combination of punctuation marks used in his/her writing. So, we takes stats of the number of commas, colons and semicolons user per sentence for each section.
- BagOfWords: This feature takes the top 100 words found in the entire text, and counts the occurence of each for every section. To not many columns (100), we reduce the dimensions by applying TruncatedSVD on the count matrix.
- Funtional BagOfWords: This feature is similar to the one above except that the vocabulary includes only functional words, modified for 16-17th century, that are known to help define an authors signature in word adjacency networks according to research. Functional words found in Shakespearan english which are different than modern english. Note, words like ’yt it’ represent it, ’wid wyth wytt wi wt wth’ represent with and are not misspellings. Functional word source: MSc_Thesis_Segarra
- ScenesLSA: This feature is the tf-idf matrix of all words in the collection that occur in atleast 75 sections, and reduced dimensionaly using TruncateSVD (LSA).
- ngramTFIDF: This feature is a tf-idf matrix of unigrams, bigrams and tri-grams that occur in atleast 75 sections, and no more than 20% of the sections. The average sentence length is approximately 3 accross the collection and hence this shoud capture some common sentenes/phrases across sections.
Note: Couple of feaures like tf-idf matrix of functional words and parts-of-speech tags were not found to be useful for the shakespeare corpus.
Clustering and Ensemble Voting
Once the different features are extracted, clustering is applied one each set of features to divide them into groups of two. One group of sections will correspond to Shakespeare and the other to non-Shakespeare authors. The majority group is given to Shakespeare, with the assumption that the majority of sections will have been written by him. After that, ensemble voting is done across the various clustering groups for different set of features. Then by using majority voting, we determine if a section is written by Shakespeare or not. For example, let’s say cluster 0 corresponds to Shakespeare plays and cluster 1 to non-Shakespeare plays. If section 1.1 belongs to cluster 0 for features 0, 1, 2 and 3, to cluster 1 for features 4 and 5, we can conclude that section 1.1 belongs to cluster 0 since it was found to be in cluster 0 for 4 different features. In case of ties, where the section is present in equal number of cluster groups for various sections, we assign it to shakespeare, given the benefit of doubt.
After ensemble voting is done, various sections corresponding to non-Shakespeare authors are determined and printed for reference.
Different types of clustering and the optimum number of clusters
KMeans, DBScan and Agglomerative clustering (a type of hierarchical clustering) are tried. Silhouette score measure is used to identify the optimum number of clusters in each of the techniques. It was found that across the various features, using the Silhouette score, was found as the optimum cluster number for k-means and agglomerative clustering. It was also found that DBscan gave only one cluster for all the features, and hence, was dropped from our clustering methods.
Visualization of the data before and after clustering across features
Different types of visualization schemes like TSNE, PCA and LSA (with Truncated SVD) are used for visualizing the data before and after clustering. Pre-clustering visualization is done to check the distribution of the various sections for the different sets of features and to determine if the clustering done above can give good results. Post-clustering (k-means & Agglomerative) visualization is done to validate if properly distinct clusters have been identified by clustering.
Lexical Features
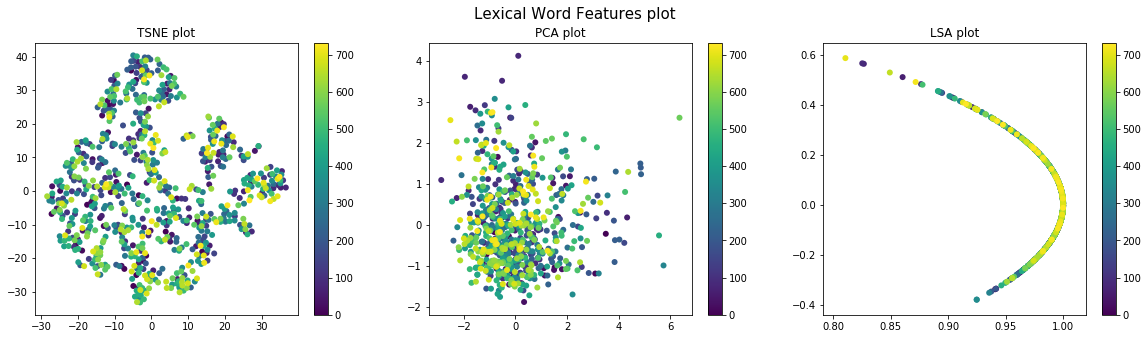
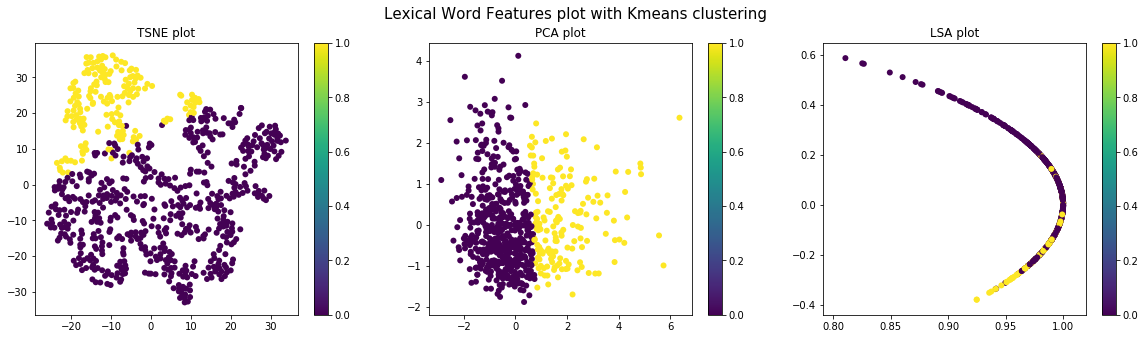
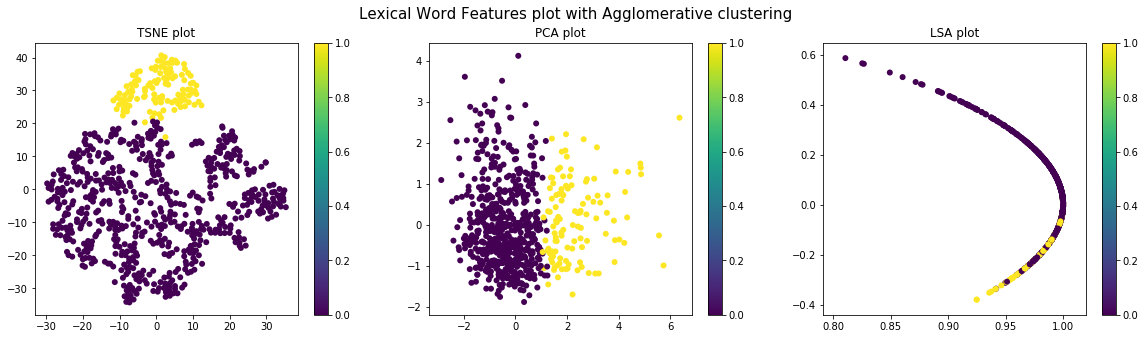
Punctual Features
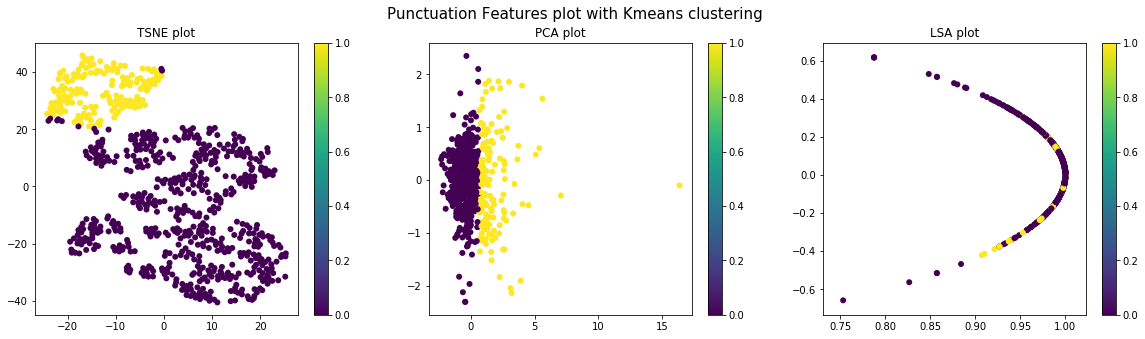
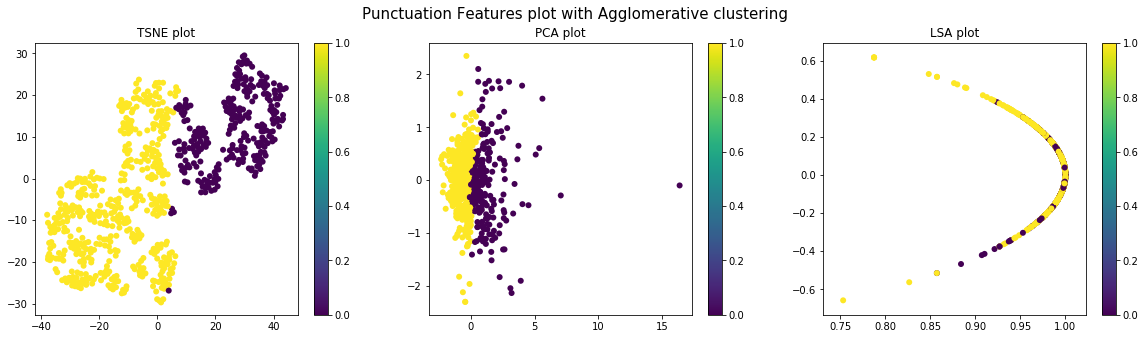
Conclusion
A novel approach of feature extraction and ensemble voting by clustering is done here to determine the various play-sections which might have not been written by Shakespeare. An in-depth feature extraction is done from the plays to identify the textual features that alltogether, encompass the writing signature of Shakespeare. K-means an Agglomerative clustering methods are applied to create two clusters. The majority cluster written by Shakespeare and the second, minority cluster, belonging to other authors. It was found that around 100 sections out of total 732 sections had patterns different to those of Shakespearan written sections, and hence, possibly written by other authors.
Leave a comment