
Summary of the Seminal paper on Dropouts
In this post, I summarize the paper titled, “Dropouts: A Simple Way to Prevent Neural Networks from Over tting” by Srivastava et al., publised in Journal of Machine Learning (2014).
Dropouts is a regularization technique for neural networks that was introduced to reduce over-fitting introduced in models with millions of parameters, but trained on limited data. The best way to regularize a fixed-sized model is to average the predictions of all possible settings of the parameters, weighing each setting by it’s posterior probability given the training data, but this would involve unlimited computation and is prohibitively expensive. Even if computation is not an issue, large networks require large amounts of training data and there may not be enough data available to train different networks on different subsets of data.
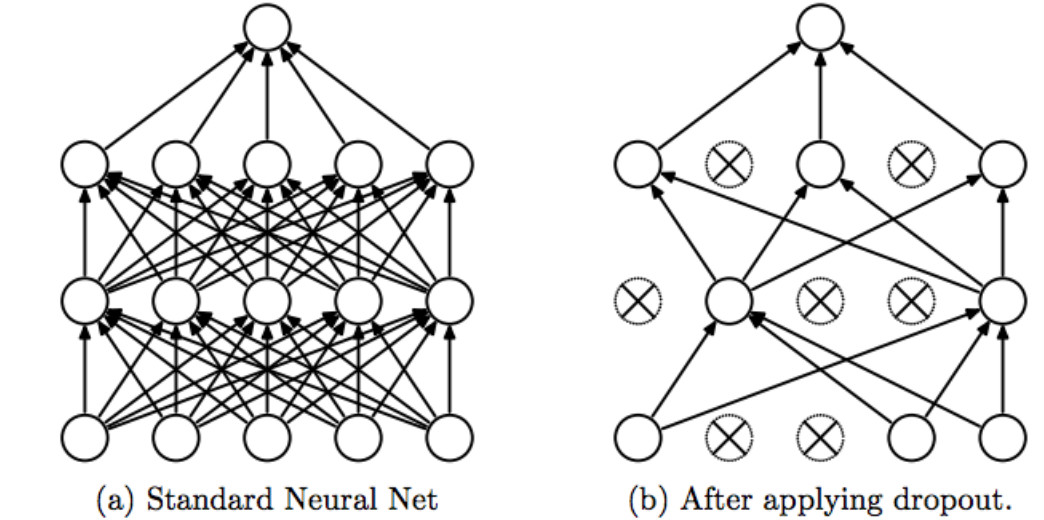
Dropouts addresses both these issues of computation and data availability. It provides a way of approximately combining exponentially many different neural networks efficiently. It does this by dropping out units at random, temporarily removing it from the network, along with all it’s incoming and outgoing connections. Training a neural network with dropout can be seen as training a collection of \(2^n\) thinned networks with weight sharing, where each thinned network gets trained very rarely, if at all. How is this handled at test time, as it is not feasible to average the predictions from exponentially many thinned models?
Instead, a simple approximate averaging method is used, where the weights of the network, with all it’s units at test time, are scaled-down versions of the trained weights. If a unit is retained with probability p during training, the outgoing weights of that unit are multiplied by p at test time. This ensures that for any hidden unit, the expected output (given dropout probability \(p\)) is the same as the actual output at test time.
The authors applied dropout on multiple classification datasets in various domain, in vision (MNIST, SVHN, CIFAR-10/100, ImageNet), speech (TIMIT), text and genetics. In all, they looked at the state-of-the-art techniques with and without dropout, observing the test error. The improvement was much smaller in the text dataset compared to that for the vision and speech data sets. In all cases, the optimal dropout probability \(p\) was found to be 0.5 for hidden units and 0.8 for input units. Dropout breaks up co-adaptations and the activations of the hidden units become sparse, which is why it leads to lower generalization errors.
Leave a comment